OpenAI’s DALL-E 3 has revolutionized the field of artificial intelligence (AI) by pushing the boundaries of what machines can create. Building upon the success of its predecessor, DALL-E, this advanced AI model uses a combination of deep learning and generative adversarial networks (GANs) to generate astonishingly realistic images from textual descriptions. With DALL-E 3, OpenAI has taken a significant step towards achieving a more comprehensive understanding of human language and visual perception. In this article, we will delve deeper into the capabilities and implications of OpenAI’s DALL-E 3, exploring its potential applications and the ethical considerations surrounding its use.
In the Generative AI world, keeping up with the latest is the name of the game. And when it comes to generating images, Stable Diffusion and Midjourney were the platform everyone was talking about – until now.
You are viewing: A Closer Look at OpenAI’s DALL-E 3
OpenAI, backed by the tech giant Microsoft, introduced DALL·E 3 on September 20th, 2023.
DALL-E 3 isn’t just about creating images; it’s about bringing your ideas to life, just the way you imagined them. And the best part? It’s fast, like, really fast. You’ve got an idea, you feed it to DALL-E 3, and boom, your image is ready.
So, in this article, we’re going to dive deep into what DALL-E 3 is all about. We’ll talk about how it works, what sets it apart from the rest, and why it might just be the tool you didn’t know you needed. Whether you’re a designer, an artist, or just someone with a lot of cool ideas, you’re going to want to stick around for this. Let’s get started.
What’s new with DALL·E 3 is that it gets context much better than DALL·E 2. Earlier versions might have missed out on some specifics or ignored a few details here and there, but DALL·E 3 is on point. It picks up on the exact details of what you’re asking for, giving you a picture that’s closer to what you imagined.
The cool part? DALL·E 3 and ChatGPT are now integrated together. They work together to help refine your ideas. You shoot a concept, ChatGPT helps in fine-tuning the prompt, and DALL·E 3 brings it to life. If you’re not a fan of the image, you can ask ChatGPT to tweak the prompt and get DALL·E 3 to try again. For a monthly charge of 20$, you get access to GPT-4, DALL·E 3, and many other cool features.
Microsoft’s Bing Chat got its hands on DALL·E 3 even before OpenAI’s ChatGPT did, and now it’s not just the big enterprises but everyone who gets to play around with it for free. The integration into Bing Chat and Bing Image Creator makes it much easier to use for anyone.
The Rise of Diffusion Models
In last 3 years, vision AI has witnessed the rise of diffusion models, taking a significant leap forward, especially in image generation. Before diffusion models, Generative Adversarial Networks (GANs) were the go-to technology for generating realistic images.
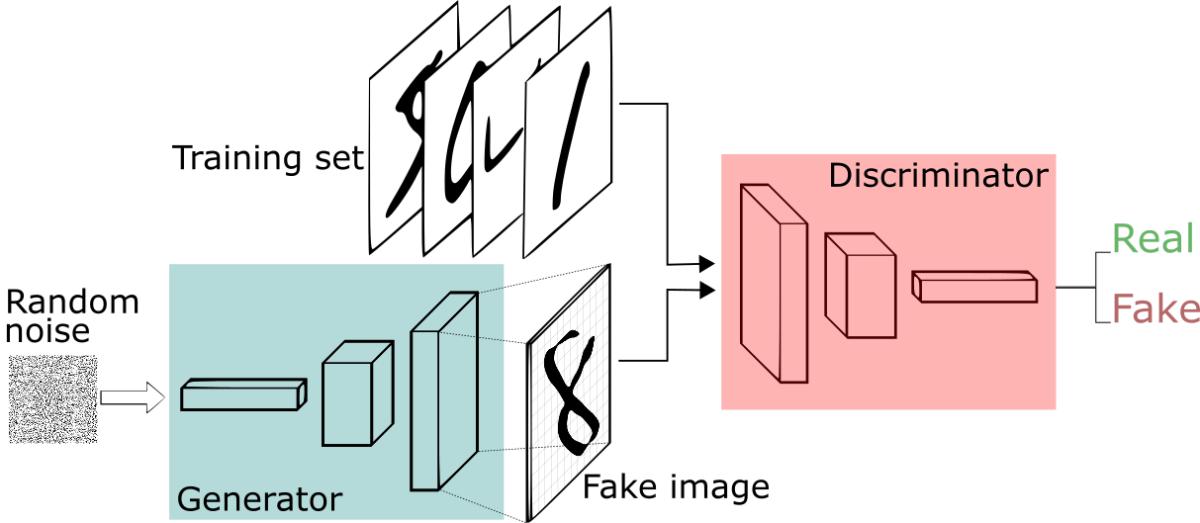
GANs
However, they had their share of challenges including the need for vast amounts of data and computational power, which often made them tricky to handle.
Enter diffusion models. They emerged as a more stable and efficient alternative to GANs. Unlike GANs, diffusion models operate by adding noise to data, obscuring it until only randomness remains. They then work backwards to reverse this process, reconstructing meaningful data from the noise. This process has proven to be effective and less resource-intensive, making diffusion models a hot topic in the AI community.
The real turning point came around 2020, with a series of innovative papers and the introduction of OpenAI’s CLIP technology, which significantly advanced diffusion models’ capabilities. This made diffusion models exceptionally good at text-to-image synthesis, allowing them to generate realistic images from textual descriptions. These breakthrough were not just in image generation, but also in fields like music composition and biomedical research.
Today, diffusion models are not just a topic of academic interest but are being used in practical, real-world scenarios.
Generative Modeling and Self-Attention Layers: DALL-E 3

Source
One of the critical advancements in this field has been the evolution of generative modeling, with sampling-based approaches like autoregressive generative modeling and diffusion processes leading the way. They have transformed text-to-image models, leading to drastic performance improvements. By breaking down image generation into discrete steps, these models have become more tractable and easier for neural networks to learn.
See more : 10 Best ChatGPT Prompts for HR Professionals
In parallel, the use of self-attention layers has played a crucial role. These layers, stacked together, have helped in generating images without the need for implicit spatial biases, a common issue with convolutions. This shift has allowed text-to-image models to scale and improve reliably, due to the well-understood scaling properties of transformers.
Challenges and Solutions in Image Generation
Despite these advancements, controllability in image generation remains a challenge. Issues such as prompt following, where the model might not adhere closely to the input text, have been prevalent. To address this, new approaches such as caption improvement have been proposed, aimed at enhancing the quality of text and image pairings in training datasets.
Caption Improvement: A Novel Approach
Caption improvement involves generating better-quality captions for images, which in turn helps in training more accurate text-to-image models. This is achieved through a robust image captioner that produces detailed and accurate descriptions of images. By training on these improved captions DALL-E 3 have been able to achieve remarkable results, closely resembling photographs and artworks produced by humans.
Training on Synthetic Data
The concept of training on synthetic data is not new. However, the unique contribution here is in the creation of a novel, descriptive image captioning system. The impact of using synthetic captions for training generative models has been substantial, leading to improvements in the model’s ability to follow prompts accurately.
Evaluating DALL-E 3
Through multiple evaluation and comparisons with previous models like DALL-E 2 and Stable Diffusion XL, DALL-E 3 has demonstrated superior performance, especially in tasks related to prompt following.

Comparison of text-to-image models on various evaluations
The use of automated evaluations and benchmarks has provided clear evidence of its capabilities, solidifying its position as a state-of-the-art text-to-image generator.
DALL-E 3 Prompts and Abilities
DALL-E 3 offers a more logical and refined approach to creating visuals. As you scroll through, you’ll notice how DALL-E crafts each image, with blend of accuracy and imagination that resonates with the given prompt.
Unlike its predecessor, this upgraded version excels in arranging objects naturally within a scene and depicting human features accurately, down to the correct number of fingers on a hand. The enhancements extend to finer details and are now available at a higher resolution, ensuring a more realistic and professional output.
The text rendering capabilities have also seen substantial improvement. Where DALL-E previous versions produced gibberish text, DALL-E 3 can now generate legible and professionally styled lettering (sometimes), and even clean logos on occasion.
The model’s understanding of complex and nuanced image requests has been significantly enhanced. DALL-E 3 can now accurately follow detailed descriptions, even in scenarios with multiple elements and specific instructions, demonstrating its capability to produce coherent and well-composed images. Let’s explore some prompts and the respective output we got:
Design the packaging for a line of organic teas. Include space for the product name and description.

DALL-E 3 images based on text prompts (Note that the left poster have wrong spelling)
Create a web banner advertising a summer sale on outdoor furniture. The image feature a beach setting with different pieces of outdoor furniture, and text announcing 'Huge Summer Savings!'

DALL-E 3 images based on text prompts
See more : Prompt Hacking and Misuse of LLMs
A vintage travel poster of Paris with bold and stylized text saying 'Visit Paris' at the bottom.

DALL-E 3 images based on text prompts (Note that both posters have wrong spellings)
A bustling scene of the Diwali festival in India, with families lighting lamps, fireworks in the sky, and traditional sweets and decorations.
DALL-E 3 images based on text prompts

A detailed marketplace in ancient Rome, with people in period-appropriate clothing, various goods for sale, and architecture of the time.
DALL-E 3 images based on text prompts
Generate an image of a famous historical figure, like Cleopatra or Leonardo da Vinci, placed in a contemporary setting, using modern technology like smartphones or laptops.
DALL-E 3 images based on text prompts
Limitations & Risk of DALL-E 3
OpenAI has taken significant steps to filter explicit content from DALL-E 3’s training data, aiming to reduce biases and improve the model’s output. This includes the application of specific filters for sensitive content categories and a revision of thresholds for broader filters. The mitigation stack also includes several layers of safeguards, such as refusal mechanisms in ChatGPT for sensitive topics, prompt input classifiers to prevent policy violations, blocklists for specific content categories, and transformations to ensure prompts align with guidelines.
Despite its advancements, DALL-E 3 has limitations in understanding spatial relationships, rendering long text accurately, and generating specific imagery. OpenAI acknowledges these challenges and is working on improvements for future versions.
The company is also working on ways to differentiate AI-generated images from those made by humans, reflecting their commitment to transparency and responsible AI use.

DALL·E 3
DALL-E 3, the latest version, will be available in phases starting with specific customer groups and later expanding to research labs and API services. However, a free public release date is not confirmed yet.
OpenAI is truly setting a new standard in the field of AI with DALL-E 3, seamlessly bridging complex technical capabilities and user-friendly interfaces. The integration of DALL-E 3 into widely used platforms like Bing reflects a shift from specialized applications to broader, more accessible forms of entertainment and utility.
The real game-changer in the coming years will likely be the balance between innovation and user empowerment. Companies that thrive will be those that not only push the boundaries of what AI can achieve, but also provide users with the autonomy and control they desire. OpenAI, with its commitment to ethical AI, is navigating this path carefully. The goal is clear: to create AI tools that are not just powerful, but also trustworthy and inclusive, ensuring that the benefits of AI are accessible to all.
That concludes the article: A Closer Look at OpenAI’s DALL-E 3
I hope this article has provided you with valuable knowledge. If you find it useful, feel free to leave a comment and recommend our website!
Click here to read other interesting articles: AI
Source: apkguild.com
#Closer #OpenAIs #DALLE
Source: https://apkguild.com
Category: Prompt Engineering